Subprogrammtypen konfigurieren
Für die Subprogramme legen Sie den Ablauf der Datenübergabe in der Konfiguration fest (siehe 'Subprogramme zuordnen'). Über das Konfigurationsprogramm eines Subprogrammtyps konfigurieren Sie die Bearbeitung der Daten.
Den meisten Subprogrammtypen ist das Konfigurationsprogramm AXRCCONF zugeordnet.
AXIMGIMP, AXVALID und AXIMPMDC werden jeweils zugleich als Subprogrammtyp und als Konfigurationsprogramm verwendet. Wenn Sie diese Subprogramme im Konfigurationsmodus starten, benötigen Sie zur Konfiguration nur eine Pfadangabe zu einem temporären Verzeichnis oder zu den gewünschten Daten.
So starten Sie die Konfigurationsprogramme:
|
|
Markieren Sie das Subprogramm und klicken Sie auf der Registerkarte START auf Konfigurieren. Das Konfigurationsprogramm wird gestartet. |

Für AXIMGIMP geben sie den Pfad zu den Bildern schon im Dialog Subprogrammtypen bearbeiten (siehe 'Subprogramme zuordnen') über den Parameter '/S' in der Kommandozeile an. AXIMGIMP muss nicht im Konfigurationsmodus gestartet werden.
|
Beispiel: |
|

Für AXVALID geben Sie optional ein temporäres Verzeichnis für die Bilder an, beispielsweise ein lokales Verzeichnis für die Arbeitsstation. Die Bilder werden beim Programmstart dorthin kopiert und zum Validieren aus diesem Verzeichnis vorgelegt.
Für AXIMPMDC geben Sie den Pfad zur benötigten Konfigurationsdatei an.
Für enaio® database synchronisation richten Sie eine Datenbankverbindung zu einer externen Datenbank ein und geben Wert-, Anfrage- und Abgleichfelder an.
Für enaio® capture-transfer-module stellen Sie PDF-Dateien und zugeordnete Daten für eine Weiterverarbeitung in enaio® classify bereit. Die Daten und Dateien werden in einem Verzeichnis bereitgestellt, auf das enaio® classify zugreift. Eingebunden werden kann eine Rechnungskonformitätsprüfung.
AXRCCONF
Das Konfigurationsprogramm AXRCCONF ist den Subprogrammtypen AXDSCAN, AXTWSCAN, AXICSCAN, AXFINER, AXNOOCR und AXIMPORT zugeordnet.
AXRCCONF starten Sie über den Eintrag Konfigurieren aus dem Kontextmenü eines Subprogramms. Dabei ist es gleichgültig, welches mit AXRCCONF verknüpfte Subprogramm Sie markiert haben. AXRCCONF verwaltet die Einstellungen für eine Konfiguration in einer Konfigurationsdatei.
Im Programmfenster finden Sie folgende Registerkarten, die den Ablaufkomponenten zugeordnet sind:
Allgemein/Scannen
Auf der Registerkarte Allgemein/Scannen tragen Sie optional ein temporäres Verzeichnis für die Bilder der gescannten Seiten ein, beispielsweise ein lokales Verzeichnis. Die Bilder werden nach dem Scannen aus diesem temporären Verzeichnis in das folgende Verzeichnis verschoben:
...\ASIndex\AXINDEX.DAT\Konfigurationsbezeichnung\BATCH_ID

Sie können über die Option Autostart erstes Subprogramm einstellen, dass das Scan-Subprogramm bei Neuanlage eines Batches sofort startet, beim Starten sofort mit dem Scannen beginnt und die Seiten und den Batch weiterreicht.
Des Weiteren stehen Ihnen zwei Optionen zur automatischen Batchanlange zur Verfügung.
Über die Option Nach Ausführung aller Subprogramme neuen Batch anlegen legen Sie fest, dass automatisch ein neuer Batch angelegt wird, sobald alle Subprogramme ausgeführt und der Batch in die Ablage verschoben wurde.
Wenn Sie die Option Bei Programmstart neuen Batch anlegen aktivieren, wird beim Start von enaio® capture automatisch ein neuer Batch angelegt, sofern die Konfigurationsauswahl eingeblendet (siehe 'Löschrechte für Batches') und die entsprechende Konfiguration ausgewählt ist. Beide Funktionen stehen nicht zur Verfügung, wenn das erste Subprogramm einen nicht gesperrten Batch enthält oder das letzte Subprogramm von einer Autostation ausgeführt wird.
Erkennen
Auf der Registerkarte Erkennen finden Sie weitere Registerkarten:
- Feldattribute
Hier definieren Sie die Indexierungsfelder.
- Festfeldattribute
Hier definieren Sie Indexierungsfelder, die konstante Werte erhalten sollen.
- Feldersetzungen
Hier können Sie automatisch indexierten Feldern, abhängig vom Wert, einen anderen Wert zuweisen.
- Regex
Für die Arbeit mit der Texterkennung können reguläre Ausdrücke angegeben werden, durch die der erkannte Text gefiltert wird.
Feldattribute
Sie definieren, bearbeiten oder löschen auf dieser Registerkarte die Indexierungsfelder für die Dokumente. Diesen Indexierungsfeldern können Sie für den Import Indexierungsfelder von enaio®-Objekten zuordnen (siehe 'Feldzuordnungen').
Eine große Anzahl von Feldern und ein großer Inhalt können bei der Verarbeitung zu Fehlern führen, weil SQL-Statements zu lang werden. Beachten Sie dieses bitte bei der Konzeption von Feldanzahl und Datentyp.
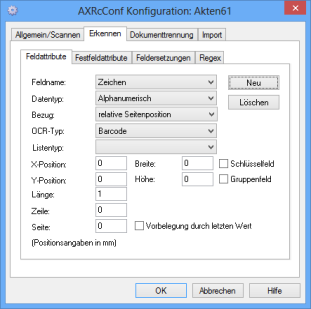
Über die Schaltfläche Neu legen Sie neue Indexierungsfelder an, über die Schaltfläche Löschen löschen Sie Indexierungsfelder. Über die Liste zum Feld Feldname wählen Sie die Indexierungsfelder, die Sie bearbeiten wollen.
Indexierungsfeldern ordnen Sie einen Datentyp zu:
|
Datentyp |
Format |
Länge |
|---|---|---|
|
Alphanumerisch |
alle Zeichen |
datenbankabhängige Anzahl von Zeichen |
|
Numerisch |
{0...9} |
max. 9 Zeichen |
|
Datum |
JJJJMMDD |
10 Zeichen |
|
Dezimal |
XXXXXXXXXX.NN |
10 Zeichen Vorkomma, 2 Zeichen Nachkomma |
Für Indexierungsfelder, die über die Barcode-Erkennung oder OCR ausgefüllt werden, legen Sie einen Erkennungsbereich auf den Seiten fest, in dem der Barcode oder die Zeichen gesucht werden.
Wenn Sie als Bezug: relative Seitenposition wählen, legen Sie den Bereich über Koordinaten fest.
|
Feld |
Beschreibung |
|---|---|
|
X-Position |
obere linke Ecke des Erkennungsbereichs horizontal in mm |
|
Y-Position |
obere linke Ecke des Erkennungsbereichs vertikal in mm |
|
Breite |
Breite des Erkennungsbereichs in mm |
|
Höhe |
Höhe des Erkennungsbereichs in mm |
|
Länge |
Länge des Indexierungsfelds in Zeichen. Ist der Datentyp 'dezimal', geben Sie die Anzahl der Vorkommastellen an. Ist der Datentyp 'Datum', geben Sie als Länge '10' an. Sie können, durch Kommata getrennt, zusätzlich zur Länge einen minimalen und einen maximalen Wert angeben. Liegt die Anzahl der erkannten Zeichen nicht in diesem Bereich, gilt der Wert als fehlerhaft und wird nicht verwendet. Beispiel: 10,4,10 Hinweis: Für ein Barcode-Datum in der Form 'TTMMJJJJ' tragen Sie '10,8,8' ein. Der Datentyp 'Datum' benötigt als interne Länge '10', das zu erkennende Datum hat minimal und maximal, also genau 8 Stellen. |
|
Zeile |
Barcodezeile (falls der OCR-Typ 'Barcode' ist) |
|
Seite |
nicht mehr unterstützt |
Haben Sie ein Beispieldokument im Archiv, können Sie über enaio® client die Koordinaten eines Bereichs kopieren und hier einfügen. Markieren Sie dort einen Bereich und kopieren Sie mit Alt+C die Koordinaten in die Zwischenablage. Fügen Sie dann diese Daten über die Einfg-Taste in eines der Felder X-Position, Y-Position, Breite oder Höhe ein.
Wählen Sie als Bezug: anderes Feld, können Sie aus einem anderen Indexierungsfeld Werte auslesen, um z. B. die Informationen aus einem Barcode auf mehrere Indexierungsfelder zu verteilen. Dieses andere Indexierungsfeld darf sich selbst dabei nicht auf ein weiteres Indexierungsfeld beziehen.
|
Feld |
Beschreibung |
|---|---|
|
Bezugsfeld |
Das Indexierungsfeld, das ausgelesen wird. |
|
Start |
Die Stelle des ersten Zeichens im Indexierungsfeld, das ausgelesen wird. |
|
Länge |
Die Anzahl der Zeichen, die ausgelesen werden. |
|
Feldlänge |
Die maximale Anzahl der Zeichen, die in das Indexierungsfeld eingetragen werden können. |
Für ein Indexierungsfeld wählen Sie einen OCR-Typ. Ein Indexierungsfeld, das auf ein anderes bezogen ist, benötigt keinen OCR-Typ.
|
OCR-Typ |
Beschreibung |
|---|---|
|
Barcode |
Barcode-Erkennung |
|
Omnifont |
OCR-Erkennung von durch Laserdruck geschriebenen Seiten |
|
Omnifont-Numerisch |
OCR-Erkennung von Zahlen. Treten andere Zeichen auf, ist die Erkennung fehlerhaft. |
|
Omnifont-Ersetzung |
OCR-Erkennung, bei der Sie statt einer kompletten Feldersetzung eine differenzierte Zeichenersetzung konfigurieren können. |
|
Dotmatrix |
OCR-Erkennung von durch Nadeldruck geschriebenen Seiten |
|
ICR |
Erkennung von handschriftlichen Zeichen |
|
ICR-Numerisch |
Erkennung von handschriftlichen numerischen Zeichen |
|
Abgleich |
Das Indexierungsfeld wird leer gelassen, um z. B. von einem Pre- oder Aftercheck-Programm gefüllt zu werden. Diesen Typ wählen Sie ebenfalls, wenn das Indexierungsfeld manuell ausgefüllt wird. |
|
Markierung |
Erkennung schwarzer Ecken. Schwarze Ecken sind geschwärzte Bereiche auf einem Dokument, welche die Erkennung mit einer hohen Wahrscheinlichkeit feststellen kann. Dieses Verfahren wird eingesetzt, um die Qualität der Dokumententrennung zu verbessern. |
|
Sammelabgleich |
Felder dieses Typs werden vom Benutzer am Anfang der Validierung ausgefüllt. Der Wert wird dann für alle Dokumente übernommen, kann aber bei der Validierung der einzelnen Dokumente überschrieben werden. |
Indexierungsfeldern können Sie über das Feld Listentyp eine Katalogliste zuordnen, die zuvor in enaio® editor erstellt und einem Feld zugewiesen wurde. Die Eigenschaften der Kataloglisten, beispielsweise Breite und Höhe von Baumkatalogen, richten sich nach den jeweiligen Katalogeinstellungen in enaio® editor. In AXVALID können Sie dann über eine Katalog-Schaltfläche zu diesem Feld die Werte aus der Katalogliste auswählen.
Indexierungsfeldern können Sie die Option Schlüsselfeld zuweisen. Ein erkannter Wert wird dann automatisch für die nächsten Seiten übernommen, solange kein neuer Wert ermittelt wird.
Der automatisch übernommene Wert wird in AXVALID aber nicht angezeigt, sondern erst für die folgenden Schritte – Dokumententrennung und Import – verwendet. Trägt ein Benutzer einen Wert in ein Schlüsselfeld von AXVALID ein, wird dieser Wert ebenfalls für die Dokumententrennung und den Import der nächsten Seiten übernommen, solange kein neuer Wert ermittelt oder eingetragen wird.
Schlüsselfelder sind in AXVALID nicht gekennzeichnet. Informieren Sie deshalb den Benutzer, wenn Sie diese Option verwenden.
Kennzeichnen Sie mehrere Felder jeweils als Gruppenfeld, wird bei der Validierung überprüft, ob diese Gruppenfelder entweder alle ausgefüllt sind beziehungsweise alle nicht ausgefüllt sind. Ist dies nicht der Fall, erhält der Benutzer einen Hinweis, sobald er zu einem anderen Dokument blättert.
Bei Feldern mit der Eigenschaft Vorbelegung durch letzten Wert wird bei der Anzeige der Seite in der Validierung jeweils der zuletzt eingetragene Wert voreingetragen und farblich gekennzeichnet und kann mit übernommen werden.
Markieren Sie die Option Bei Verarbeitung Bestätigung einholen, kann der Benutzer in AXVALID den Festwert pauschal für alle Seiten ändern.
Festfeldattribute
Über die Registerkarte Festfeldattribute definieren Sie Festfelder, d. h. Indexierungsfelder, bei denen Sie einen Wert vorgeben.
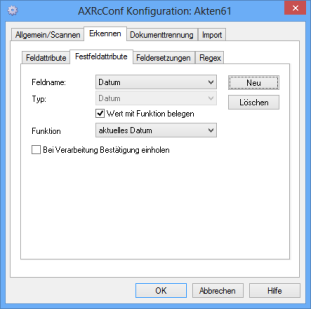
Über die Schaltfläche Neu legen Sie neue Festfelder an, über die Schaltfläche Löschen löschen Sie Festfelder. Über die Liste zum Feld Feldname wählen Sie die Festfelder, die Sie bearbeiten wollen.
Festfeldern ordnen Sie einen Typ zu:
|
Datentyp |
Format |
Länge |
|---|---|---|
|
Alphanumerisch |
alle Zeichen |
maximal 248 Zeichen |
|
Numerisch |
{0..9} |
maximal 248 Zeichen |
|
Datum |
wählbar über Funktion |
|
Tragen Sie im Feld Wert den Wert für das Festfeld ein.
Wollen Sie ein Feld anlegen, bei dem der Benutzer einen Wert für alle Dokumente angibt, können Sie ein Feld des Typen Sammelabgleich einrichten.
Wählen Sie die Option Wert mit Funktion belegen, ordnen Sie dem Festfeld eine Funktion aus der Liste zum Feld Funktion zu. Der entsprechende Datentyp wird automatisch gewählt.
|
Funktion |
Datentyp |
|---|---|
|
aktuelles Datum |
Datum |
|
aktuelles Jahr |
alphanumerisch |
|
aktuelles Quartal |
alphanumerisch |
|
aktuelles JJJJMM |
numerisch |
|
aktuelles JJJJMMTT |
numerisch |
|
aktueller Monat |
alphanumerisch |
|
aktuelles Quartal o. Jahr |
alphanumerisch |
Markieren Sie die Option Bei Verarbeitung Bestätigung einholen, kann der Benutzer in AXVALID den Festwert pauschal für alle Seiten ändern.
Die einzelnen Festfelder können in AXVALID bearbeitet werden.
Festfelder, die bei der Validierung keine Rolle spielen und auch nicht angezeigt werden sollen, können Sie ebenfalls über den Importassistenten (siehe 'Der Importassistent') einrichten.
Feldersetzungen/Zeichenersetzungen
Auf der Registerkarte Feldersetzungen weisen Sie indexierten Feldern, abhängig vom Wert, einen anderen Wert zu. Ersetzt wird immer nur der komplette Feldwert durch den Ersetzungswert.
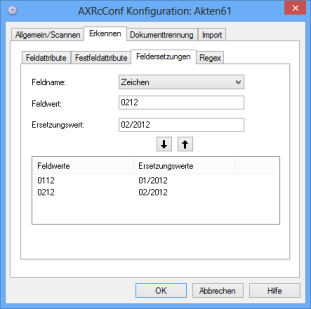
Aus der Liste zum Feld Feldname wählen Sie ein Indexierungsfeld.
Im Feld Feldwert tragen Sie den Wert ein, der automatisch ersetzt wird.
Im Feld Ersetzungswert tragen Sie den Wert ein, der den oberen Wert ersetzt.
Über die Pfeil-Schaltfläche tragen Sie die Kombination aus Feldwert und Ersetzungswert in die Liste im unteren Bereich ein. Sie können weitere Kombinationen hinzufügen. Der untere Bereich kann nicht bearbeitet werden. Wollen Sie Kombinationen ändern oder löschen, können Sie diese markieren und mit der Pfeil-Schaltfläche aus der Liste austragen.
Bei Feldern mit dem OCR-Typ Omnifont-Ersetzung ist eine Ersetzung von Zeichenfolgen innerhalb der Feldwerte möglich. Mehrere Zuordnungen von Zeichenfolge und Ersetzungswert sind möglich. Diese Zuordnungen werden in der aufgelisteten Reihenfolge von oben nach unten abgearbeitet.
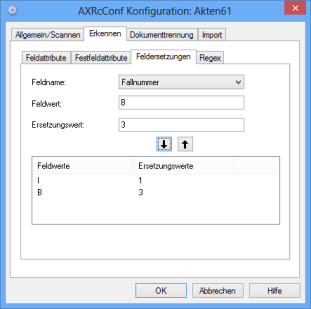
Regex
Sie wählen ein Feld aus und geben einen regulären Ausdruck ein. Ein durch die Texterkennung erkannter Text wird durch diesen regulären Ausdruck gefiltert.
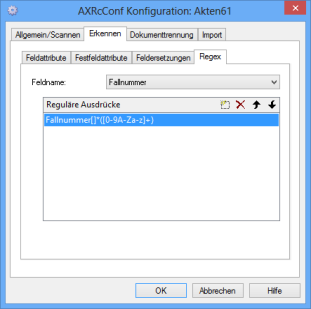
Diese Funktion steht nur für die Zusammenarbeit mit der Text- und der Barcode-Erkennung zur Verfügung.
Dokumententrennung
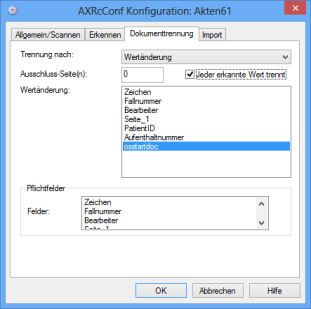
Auf der Registerkarte Dokumententrennung geben Sie Kriterien an, nach denen die einzelnen gescannten Seiten zu Dokumenten zusammengefasst werden.
Wählen Sie aus der Liste zum Feld Trennung nach als Kriterium:
- nach Seitenanzahl
- Feldwert
- Wertänderung
Das gewählte Kriterium spezifizieren Sie über die folgenden Felder.
Die Kriterien für die Dokumententrennung können nicht kombiniert werden.
Dokumententrennung nach Seitenanzahl
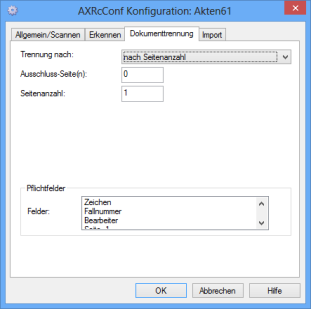
Falls alle Dokumente die gleiche Seitenanzahl haben, tragen Sie diesen Wert in das Feld Seitenanzahl ein.
Tragen Sie im Feld Ausschluss-Seite(n) die Seiten ein, die nicht in das neue Dokument übernommen werden sollen.
Beispiel: 1;4;9-11
Dokumente, bei denen ein markiertes Pflichtfeld beim Import leer ist, werden nicht importiert, sondern verbleiben im Batch.
Dokumententrennung nach Feldwerten
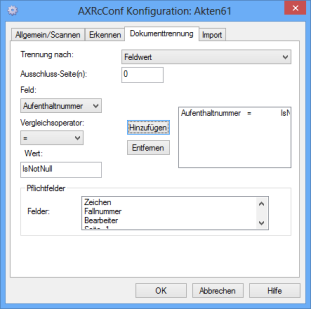
Bei der Trennung nach Feldwert, geben Sie Bedingungen für Indexierungsfelder an. Ist eine Bedingung auf einer Seite erfüllt, beginnt mit dieser Seite ein neues Dokument. Alle folgenden Seiten werden dem Dokument zugerechnet, bis eine andere oder die gleiche Bedingung erneut erfüllt ist. Das erste Dokument beginnt mit der ersten Seite.
Eine Feldwertbedingung besteht aus dem Feld, dem Vergleichsoperator ('=', '<', '<=', '>', '>=', 'IsNull', 'IsNotNull') und dem Wert. Die Einträge in diesen Feldern übertragen Sie über die Schaltfläche Hinzufügen in die Liste der Feldwertbedingungen. Mehrere Feldwertbedingungen werden logisch durch ODER verknüpft.
Wählen Sie für Ausschluss-Seite(n) einen Wert ungleich '0', werden die ersten n-Seiten ab Dokumentenbeginn nicht in das neue Dokument übernommen.
Dokumente, bei denen ein markiertes Pflichtfeld beim Import leer ist, werden nicht importiert, sondern verbleiben im Batch.
Dokumententrennung nach Wertänderungen
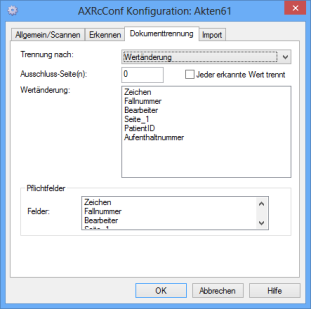
Bei der Trennung nach Wertänderung geben Sie Indexierungsfelder an, bei denen eine Wertänderung den Anfang eines neuen Dokuments kennzeichnet. Folgt einem indexierten Feld einer Seite ein leeres Feld auf der nächsten Seite, wird die Seite immer der Seite mit dem letzten erkannten Wert zugeordnet.
Markieren Sie die Option Jeder erkannte Wert trennt, so findet kein Vergleich mit dem Inhalt des letzten Wertänderungsfelds statt und ein beliebiger Eintrag in dem Wertänderungsfeld wird als Trennungskriterium genommen. Ein leeres Feld ist dabei kein Trennungskriterium.
Wählen Sie für Ausschluss-Seite(n) einen Wert ungleich '0', so werden die ersten n-Seiten ab Dokumentenbeginn nicht in das neue Dokument übernommen.
Dokumente, bei denen ein markiertes Pflichtfeld beim Import leer ist, werden nicht importiert, sondern verbleiben im Batch.
Das Kontrollkästchen 'Dokumentanfang'
Sie können ein Kontrollkästchen für die Dokumententrennung einrichten, das bei der Validierung manuell oder auch skriptgesteuert markiert werden kann und dadurch den Anfang eines Dokuments kennzeichnet.
Das Kontrollkästchen Dokumentanfang wird automatisch bei der Validierung an oberster Stelle im Datenbereich angezeigt.
Dazu richten Sie ein Feld mit folgenden Attributen ein:
|
Feldname osstartdoc, Datentyp alphanumerisch, OCR-Typ Abgleich, Länge 1.
|
|
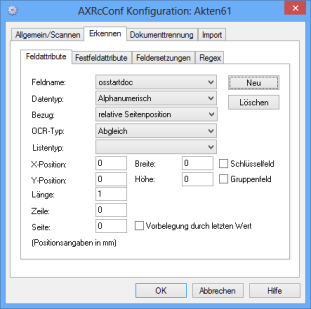
Auf der Registerkarte Dokumententrennung geben Sie dieses Feld als Wertänderungsfeld an:
|
Trennung nach Wertänderung, Wertänderung osstartdoc, Zusätzlich markieren Sie die Option Jeder erkannte Wert trennt.
|
|
Import
Auf der Registerkarte Import geben Sie im Feld ODBC-Verbindung eine Datenquelle an, durch die eine Datenbanktabelle für das Erkennen erzeugt wird. In der Datenbanktabelle sind die Seiten, Indexierungsfelder und Indexierungswerte einander zugeordnet. Das Tabellen-Verzeichnis muss im Verzeichnis ...\ASINDEX\AxIndex.dat liegen.
In Unicode-Installationen werden Teile von enaio® capture sowohl als 32-Bit als auch 64-Bit Komponenten installiert. Daher benötigen Sie zwei gleiche Datenquellen, die einmal mit dem 64-Bit-ODBC-Tool und einmal mit dem 32-Bit-ODBC-Tool erstellt werden. Sollte dies nicht möglich sein, dann installieren Sie bitte die entsprechende Microsoft Database Access Engine aus dem Verzeichnis Prerequites der Installationsdaten.
Von der eingesetzten Datenbank hängt ab, wie viele Zeichen ein alphanumerisches Feld enthalten kann (siehe 'Feldattribute').
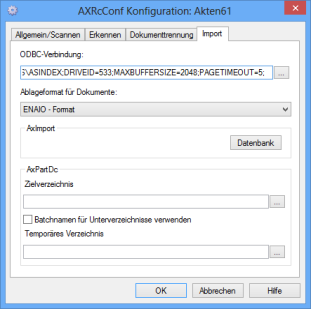
Die Seiten können im enaio®-Format abgelegt werden oder als PDF-Dateien. Falls FineReader installiert und entsprechend lizenziert ist, werden PDF-Dateien erzeugt, deren Text markiert und kopiert werden kann. Falls nicht, sind die PDF-Dateien Bilddateien mit PDF-Header.
Wählen Sie das enaio®-Format, werden die Seiten in den modulspezifischen Standard-Dateiformaten, aber mit archivspezifischen Endungen gelegt.
Im Bereich AxPartDc können Sie ein Ziel- und ein temporäres Verzeichnis für AXPARTDC angeben (siehe 'AXPARTDC').
In das Zielverzeichnis werden die Text-Dateien / dBase-Dateien (32-Bit) gelegt, die Bilddateien werden in Unterverzeichnissen gelegt, die mit der Batch-ID bezeichnet sind.
Mit der Option Batchnamen für Unterverzeichnisse verwenden wird festgelegt, dass die angegebenen Batchnamen statt der Batch-ID für die Bezeichnung der Unterverzeichnisse verwendet werden und die entsprechenden Text-Dateien / dBase-Dateien (32-Bit) ebenfalls in die Unterverzeichnisse gelegt werden.
Falls von mehreren Arbeitsplätzen Daten in ein zentrales Verzeichnis gelegt werden, müssen die Verzeichnisnamen eindeutig sein.
Über die Schaltfläche Datenbank öffnen Sie den Importassistenten, über den Sie den Dokumenten enaio®-Dokumenttypen zuordnen und den Standort im Archiv festlegen.
Der Importassistent
Der Importassistent bietet viele Möglichkeiten Daten in das Archiv zu importieren. Er wird ebenfalls für die Konfiguration von automatischen Aktionen des Typs 'Daten- / Dokumentenimport' verwendet. Einige Optionen dienen dem Import von Daten, nicht aber dem Import von Dateien. Diese Optionen sind im Folgenden nicht ausführlich beschrieben, da in der Regel mit enaio® capture Dokumente importieren werden.
System-ID
Im ersten Dialog des Importassistenten können Sie eine System-ID für alle Dokumente angegeben. Dokumente mit einer System-ID bestehen in enaio® nur aus der Indexierung. Die Dateien selbst haben einen Standort in einem anderen Archivsystem. Über die System-ID wird ein Querverweis auf dieses Archivsystem eingerichtet. Für den Import von Bilddateien benötigen Sie keine System-ID.
Klicken Sie auf die Schaltfläche Weiter.
Festfelder
Über den zweiten Dialog können Sie weitere Festfelder einrichten. Festfelder, die Sie über AXRCCONF anlegen (siehe 'Festfeldattribute'), können bei der Validierung angezeigt und bearbeitet werden. Festfelder, die Sie mit dem Importassistenten anlegen, werden erst beim Import erzeugt.

Bei der Konfiguration von Festfeldern geben Sie ebenfalls einen Datentyp an, einen Wert oder eine Funktion.
Klicken Sie auf die Schaltfläche Weiter.
Objektverbindungen
In enaio® können Sie Objekte die Sie importieren wollen, über eine Notiz mit anderen Objekten verbinden.
So erstellen Sie Objektverbindungen:
|
1. |
Wählen Sie die Option Neue Objektverbindung erstellen und geben Sie einen Namen für die Objektverbindung ein.
Klicken Sie auf die Schaltfläche Weiter. |
|
2. |
Markieren Sie den Objekttyp, auf den Sie über die Notizen der importierten Dokumente verweisen wollen.
Klicken Sie auf die Schaltfläche Weiter. |
|
3. |
Erstellen Sie eine oder mehrere Feldzuordnungen. Über die Feldzuordnungen geben Sie an, mit welchen Daten der Importfelder eine Recherche in den Objektfeldern der Objekte des gewählten Typs durchgeführt werden soll. Auf die Objekte, die so ermittelt werden, kann über die Notizen der importierten Dokumente verwiesen werden.
Klicken Sie auf die Schaltfläche Weiter. |
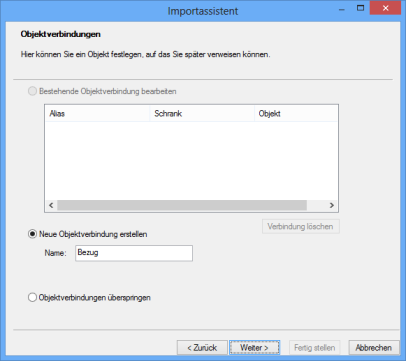
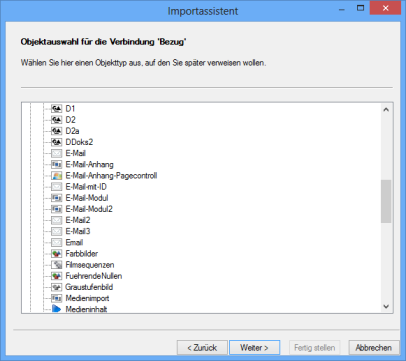
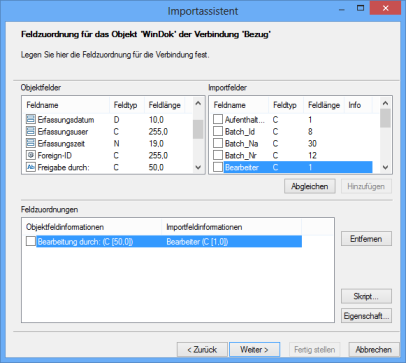
Der Dialog Objektverbindungen wird erneut angezeigt, die eingerichtete Objektverbindung ist aufgelistet. Sie können weitere Objektverbindungen erstellen. Benötigen Sie keine weiteren Objektverbindungen, markieren Sie die Option Objektverbindungen überspringen und klicken auf Weiter.
In weiteren Dialogen des Importassistenten erstellen Sie bei den Feldzuordnungen eine Zuordnung zwischen dem Objektfeld 'Notiz' und der erstellten Objektverbindung.
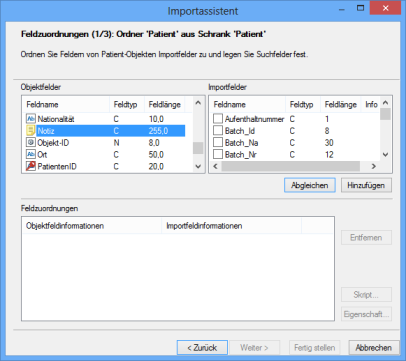
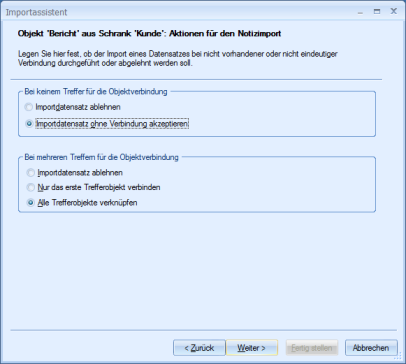
Sie legen ebenfalls fest, wie der Import verläuft, falls bei der Recherche nach Objekten für die Notizverbindung kein Treffer erzielt wurde oder mehrere Treffer erzielt wurden.
Objektauswahl
Nach den Objektverbindungen folgt zuerst die Schrankauswahl.
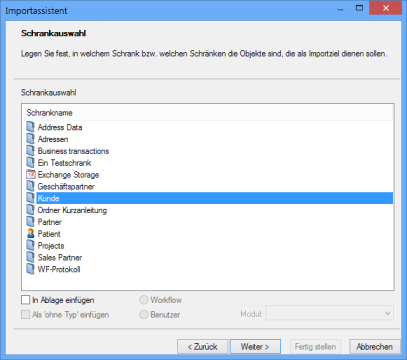
Statt in einen Schrank können Dokumente ebenfalls in die Ablage importiert werden. Von dort kann sie dann der Benutzer in enaio® client an den gewünschten Standort verschieben.
Sie können mehrere Schränke auswählen
Nach der Schrankauswahl folgt die Objektauswahl.
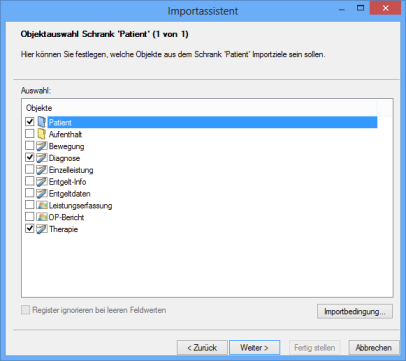
Sie wählen für jeden Schrank den Dokumenttyp, für den Sie Dokumente aus den Importdaten erzeugen wollen und optional Registertypen und den Ordnertyp.
Wählen Sie weder Registertypen noch den Ordnertyp, benötigen Sie im Archiv Dokumente des gewählten Dokumenttyps, um über deren Standort den Standort für die Importdokumente festzulegen.
Feldzuordnungen
Danach erstellen Sie Feldzuordnungen für alle gewählten Objekte.
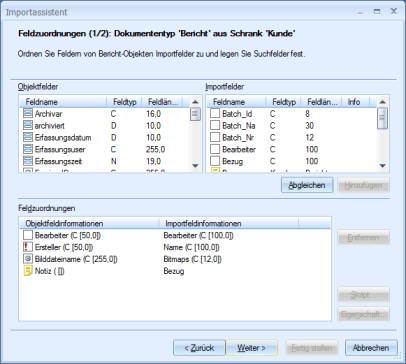
Sie ordnen den von Ihnen erstellen Importfeldern Felder aus der Objektdefinition der gewählten Objekttypen zu. Für jeden gewählten Objekttyp erstellen Sie Feldzuordnungen. Für die Bilddatei ordnen Sie dem Importfeld Bitmaps das Objektfeld Bilddateiname zu.
Mit den Daten der Importfelder werden so Objekte erzeugt, die in den Objektfeldern entsprechend indexiert sind.
Kennzeichnen Sie keine Feldzuordnungen als Suchfelder, werden immer neue Objekte erzeugt. Kennzeichen Sie Feldzuordnungen als Suchfelder, wird über die Zuordnung eine Recherche gestartet. Die neuen Objekte können relativ zum Standort der gefundenen Objekte abgelegt werden oder die Importdaten die gefundenen Objekte aktualisieren. Die Aktion legen Sie über den Folgedialog Objektaktion fest.
Eine Feldzuordnung kennzeichnen Sie über das Kontextmenü oder den Dialog Eigenschaften als Suchfeld. Den Dialog öffnen Sie über die entsprechende Schaltfläche.
Objektaktion
Falls Sie Suchfelder konfigurieren, legen Sie im Dialog Objektaktionen fest, welche Aktionen bei einem, mehreren oder keinem Treffer ausgeführt werden.
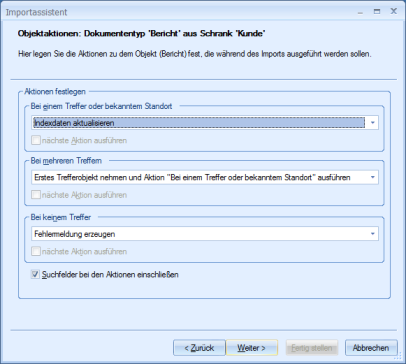
Bei einem Treffer:
- Indexdaten aktualisieren
Die Indexdaten des gefundenen Objekts werden mit den Importdaten aktualisiert.
- Indexdaten nicht aktualisieren
Die Indexdaten des gefundenen Objekts werden nicht aktualisiert.
- Masterinsert durchführen
Ist das gefundene Objekt ein Dokument ohne Seiten, werden die Indexdaten aktualisiert und das Bild zugeordnet.
Ist das gefundene Objekt ein Dokument mit Seiten, wird am Standort ein neues Dokument angelegt.
- Neuen Indexdatensatz anlegen
Am gefundenen Standort wird ein neues Objekt mit der Indexierung des Importdatensatzes angelegt.
Bei mehreren Treffern:
- Aktuellen Datensatz nicht in diesen Schrank importieren
Es wird weder ein neues Objekt angelegt noch ein Objekt in diesem Schrank aktualisiert.
- Erstes Trefferobjekt nehmen und Aktion "Bei einem Treffer oder bekannter Standort" ausführen
Es wird der erste Treffer genommen und die dort festgelegte Aktion ausgeführt.
- Indexdaten des ersten Trefferobjekts aktualisieren
Die Indexdaten des ersten Treffers werden mit den Importdaten aktualisiert.
- Keine Aktion durchführen
Es wird keine Aktion für diesen Objekttyp ausgeführt.
- Kopien löschen
Diese Option geht davon aus, dass mehrere identische Ordner ohne Inhalt oder Dokumente ohne Seiten gefunden wurden. Dann bleibt nur jeweils ein Objekt erhalten.
- Neuen Indexdatensatz anlegen (Standort des ersten Trefferobjekts)
Am Standort des ersten Trefferobjekts wird ein neues Objekt mit der Indexierung des Importdatensatzes angelegt.
Bei keinem Treffer:
- Aktuellen Datensatz nicht in diesen Schrank importieren
Es wird weder ein neues Objekt angelegt noch ein Objekt aktualisiert.
- Fehlermeldung erzeugen
Der Datensatz wird als fehlerhaft markiert. Der Import geht mit dem nächsten Datensatz weiter.
- Keine Aktion durchführen
Es wird keine Aktion für diesen Objekttyp ausgeführt.
- Neuen Indexdatensatz anlegen
Es wird ein neues Objekt mit der Indexierung des Importdatensatzes angelegt. Der Standort wird über die Daten des Importdatensatzes festgelegt.
Für jeden Fall legen Sie fest, ob die nächste Aktion ausgeführt werden soll. Die nächste Aktion wäre ein Import von Daten in einen weiteren Schrank.
Sie geben ebenfalls an, ob Suchfelder eingeschlossen werden. Sind Suchfelder eingeschlossen, werden ebenfalls die Indexdaten in den Suchfeldern aktualisiert.
Dokumentdatei-Verarbeitung
Für die Dokumentdateien legen Sie fest, wie mit diesen bei bereits vorliegenden Dokumenten verfahren wird. Sie geben an, ob bereits vorhandene Dokumentdateien ersetzt werden, die vorhandenen beibehalten werden oder ob die neuen Dokumentdateien angehängt werden.
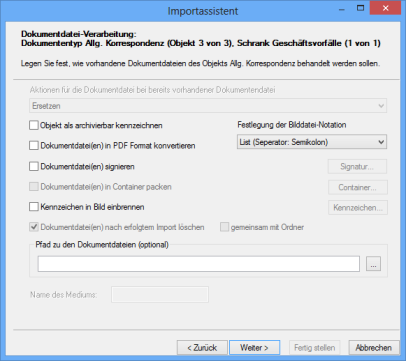
Die Notation ist immer die 'AS Notation', einen Pfad zu Dokumentdateien geben Sie nicht an.
Bei Container-Dokumenten öffnen Sie über die Schaltfläche Container den Container-Eigenschaftsdialog und legen dort, wie auch beim Anlegen eines Container-Dokuments in enaio® client, die Eigenschaften fest. Der Container wird als ZIP-Archiv verwaltet und kann beliebige Dateiformate aufnehmen.
Dokumentdateien können signiert werden, falls Sie auf ein entsprechendes Signatursystem zugreifen können. Die Signatur erfolgt über Mentana, das lokal am Arbeitsplatz oder als WebService laufen kann.
Dokumente im TIFF-, JPEG- oder PDF-Format können Sie mit einer Kennzeichnung versehen. Dazu markieren Sie die entsprechende Option und öffnen über die Schaltfläche Kennzeichen einen Dialog, in dem Sie die Eigenschaften der Kennzeichnung festlegen können.
Reihenfolge
Haben Sie Suchfelder und Objektaktionen für mehrere Objekttypen konfiguriert, legen Sie ebenfalls die Reihenfolge fest, in der die Recherche nach Objekten über die Suchfelder erfolgt und die Objektaktionen ausgeführt werden.
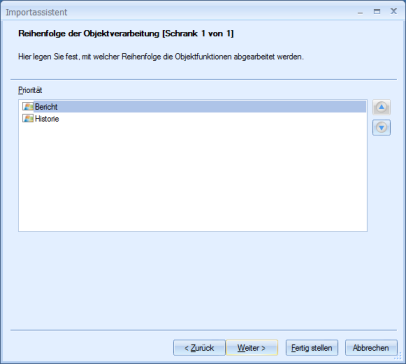
Geben Sie eine Priorität in der Reihenfolge Ordner/Register/Dokument an, werden zuerst Ordner gesucht und die Ordner-Objektaktionen ausgeführt, dann Register relativ zum Ordner und dann Objekte relativ zum Register oder Ordner.
Geben Sie eine andere Priorität an, werden Objektaktionen nicht relativ zueinander ausgeführt.
Workflowprozess anschließen
An jeden Datenimport können Sie den Start eines Workflowprozesses anschließen. Der Workflowprozess wird mit der Übergabe von Importdaten gestartet. Von den Objekten, die Sie mit dem Datenimport erzeugen, können Verweise in die Workflowakte eingefügt werden.
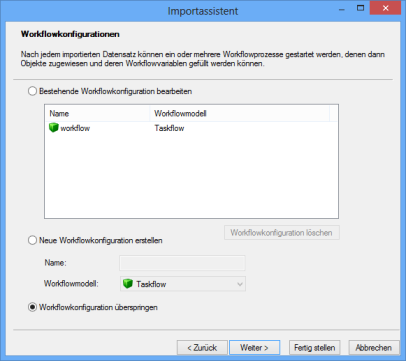
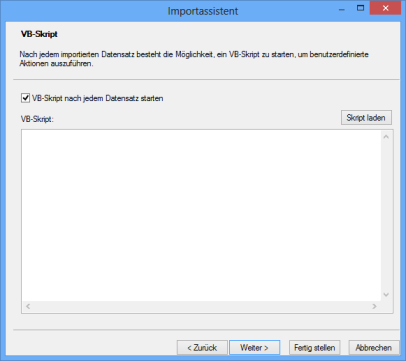
VB-Skripte
Nach dem Import oder nach jedem importieren Datensatz kann ein VB-Skript ausgeführt werden.
Sie können ein vorliegendes Skript laden oder über den Zwischenspeicher in den Skriptbereich kopieren und dort bearbeiten.
Datenbankstatistik
Hier legen Sie fest, ob und wie die Datenbankstatistik aktualisiert werden soll. Die Datenbankstatistik hat einen großen Einfluss auf die Performance der Datenbank.
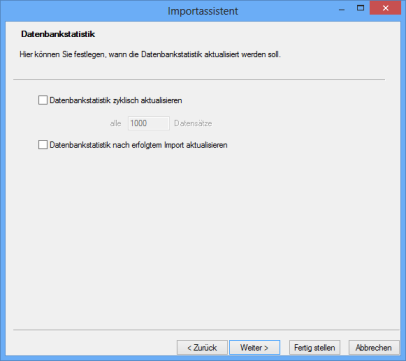
Sie können folgendes einstellen:
- Datenbankstatistik zyklisch aktualisieren
Sie geben im Feld alle ... Datensätze ein, nach wie vielen Datensätzen die Aktualisierung stattfinden soll.
- Datenbankstatistik nach erfolgtem Import aktualisieren
Es wird nach Ende des Imports eine Aktualisierung durchgeführt.
Protokolleinstellungen
Bei jedem Import wird, unabhängig von der Protokollierung im enaio®-System, im Importverzeichnis eine Protokolldatei osimplog.xml erstellt. Kann nicht in das Importverzeichnis geschrieben werden, wird die Datei in das lokale Arbeitsverzeichnis geschrieben. Erzeugt wird ebenfalls automatisch das Stylesheet osimplog.xslt, über das die Protokolldatei als HTML-Datei übersichtlich angezeigt werden kann.
Falls ein Import aufgrund von Fehlern abgebrochen wird, kann der Import über die Informationen aus der Protokolldatei und der Importablaufsicherungsdatei (s. u.) nach dem Korrigieren der Daten erneut gestartet und an der Abbruchstelle fortgesetzt werden.
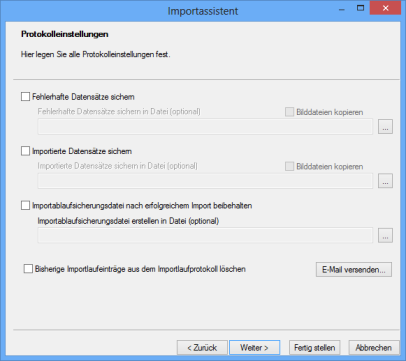
Folgende Einstellungen sind möglich:
- Fehlerhafte Datensätze sichern
Fehlerhafte Datensätze werden gesichert. Die Datei wird in das Batch-Verzeichnis geschrieben, der Name der Datei trägt die Bezeichnung name_err.
Fehlerhafte Datensätze sind Daten, deren Datenbankformat nicht mit den Einstellungen kompatibel ist.
Optional können sie im Feld Fehlerhafte Datensätze sichern in Datei eine Datei angeben, in die gesichert werden soll, und Kopien der Bilddateien erzeugen.
- Importierte Datensätze sichern
Korrekt importierte Datensätze werden gesichert. Die Datei wird in das Batch-Verzeichnis geschrieben.
Optional können sie im Feld Importierte Datensätze sichern in Datei eine Datei angeben, in die gesichert werden soll, und Kopien der Bilddateien erzeugen.
- Importablaufsicherungsdatei erstellen
Eine Ablaufsicherungsdatei wird geschrieben. Die Datei wird im binären Format erstellt und in das Batch-Verzeichnis geschrieben.
Optional können sie im Feld Importablaufsicherungsdatei erstellen in Datei eine Datei angeben, in die gesichert werden soll.
- Vorhergehende Importlaufeinträge aus der Importlaufprotokollierung löschen
Die Protokolldatei osImpLog.xml wird nicht fortlaufend erweitert, sondern für jeden Importablauf wird nur die letzte Import-Zusammenfassung gespeichert.
Optional können Sie über die Schaltfläche Email versenden einstellen, dass Sie über Importfehler per E-Mail benachrichtigt werden.
Zusammenfassung
Zum Abschluss wird eine Zusammenfassung Ihrer Importeinstellungen angezeigt.
Sie können zwischen der Tabellarischen Ansicht und der XML-Ansicht wählen, die Daten drucken und speichern.
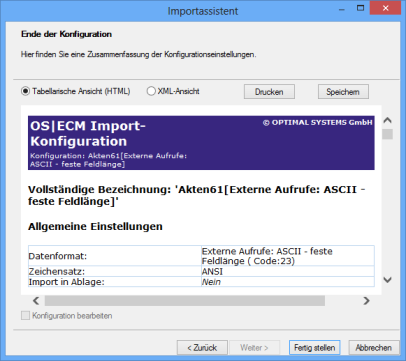
Klicken Sie auf die Schaltfläche Fertig stellen, wird die Konfiguration gespeichert.
AXICSRV
Wenn die Kofax-Engine installiert und konfiguriert wurde und Sie AXICSRV als Konfigurationsprogramm von AXICSRV eintragen, können Sie auf Kofax-Filter zugreifen und die Eigenschaften von Barcodes angeben.
Ohne die Kofax-Engine werden keine Konfigurationsoptionen angeboten.
Starten Sie AXICSRV im Konfigurationsmodus, wird das folgende Fenster geöffnet:
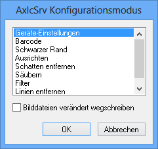
Die aufgelisteten Filter können vor dem Erkennen angewandt werden. Markieren Sie das Kontrollkästchen Bilddateien verändert wegschreiben, werden die Bilddateien den Einstellungen der Filter entsprechend gespeichert.
Doppelklicken Sie auf einen Eintrag aus der Liste, um einen Filter auszuwählen und zu konfigurieren.
Über den Eintrag Barcode geben Sie die Eigenschaften von Barcodes an.
Die Filter entsprechen denen im Kofax-Scandialog.
Die gewählten Einstellungen werden konfigurationsspezifisch gespeichert.
enaio® database synchronisation
Mit enaio® database synchronisation gleichen Sie Daten in der enaio® capture-Datenbank mit Daten aus einer externen Datenbank ab.
Für enaio® database synchronisation geben Sie als Konfigurationsprogramm ebenfalls enaio® database synchronisation an. Sie geben Verbindungsdaten zur Datenbank an und für den Abgleich die gewünschten Datenbankfelder.
Schema:

Die Konfiguration kann im Assistenten- oder im Experten-Modus erfolgen. Der Assistenten-Modus unterstützt Sie bei der Formulierung der SQL-Anweisungen.
Notwendig ist die Installation von M365 Access Runtime. Die Installation der M365 Access Runtime erfolgt über das MS Office-Setup. Beachten Sie dazu auch die Hinweise unter MS 365 Access Runtime.
Verbindungsdaten
Wenn Sie enaio® database synchronisation im Konfigurationsmodus starten, dann geben Sie die externe Datenquelle an, aus der Daten übernommen werden sollen. Datenbankinformationen werden nach der Verbindung angezeigt.
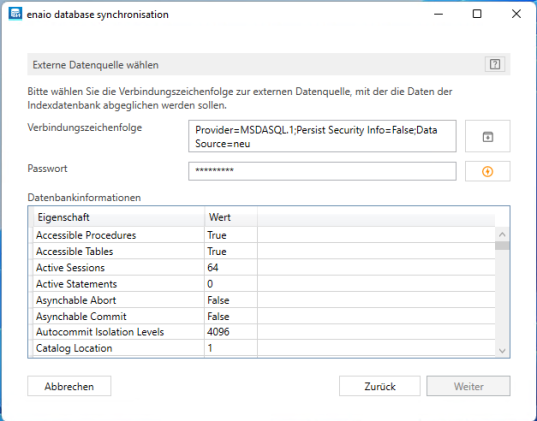
Im nächsten Schritt wählen Sie aus der externen Datenbank Tabellen und Spalten aus, aus denen Daten übernommen werden sollen.
Sie können Tabellen mit allen Spalten oder nur einzelne Tabellenspalten über Pfeiltasten auswählen.

Im nächsten Schritt erstellen Sie eine SQL-Anweisung, mit der ein Feld aus der externen Datenbank mit einem Wert aus einem Datenfeld der enaio® capture-Batch-Datenbanktabelle angefragt wird.
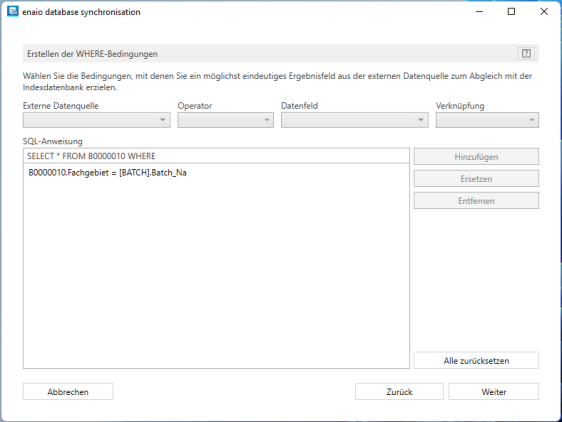
Im nächsten Schritt erstellen Sie eine SQL-Update-Anweisung, mit der ein Feld aus der enaio® capture-Batch-Datenbanktabelle mit dem entsprechenden Wert der SQL-Anfrage aktualisiert wird.
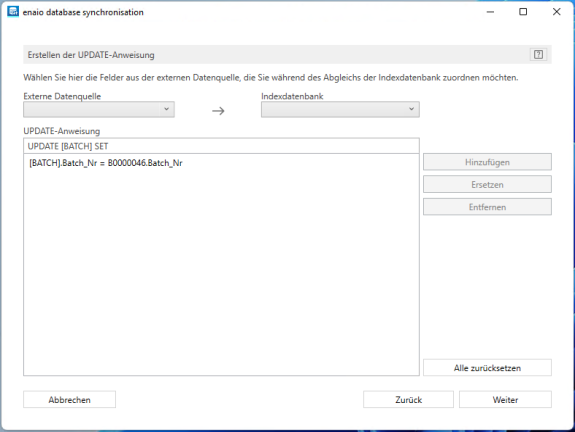
Der letzte Schritt zeigt eine Zusammenfassung der Konfiguration an.
Sie können jeweils zwischen den Schritten über Schaltflächen navigieren. Über die Schaltfläche Fertigstellenspeichern Sie die Konfiguration.
enaio® capture-transfer-module
Mit enaio® capture-transfer-module ordnen Sie PDF-Dateien notwendige Daten für eine Weiterverarbeitung in enaio® classify zu. Die Daten und Dateien werden in einem Verzeichnis bereitgestellt, auf das enaio® classify zugreift.
enaio® capture-transfer-module kann ebenfalls über den Service 'ai-connector' die kairos AI Cloud Services einbinden. Diese Einbindung extrahiert rechnungsspezifische Indexdaten aus PDF-Dateien und ermöglicht eine Rechnungskonformitätsprüfung. Bereits vorliegende PDF-Dateien können indexiert und direkt in enaio® angelegt werden.
enaio® capture-transfer-module - capture-transfer-module.exe aus dem Verzeichnis \ctm - tragen Sie ebenfalls als Konfigurationsprogramm ein.
Die Konfiguration erfolgt über acht Bereiche.
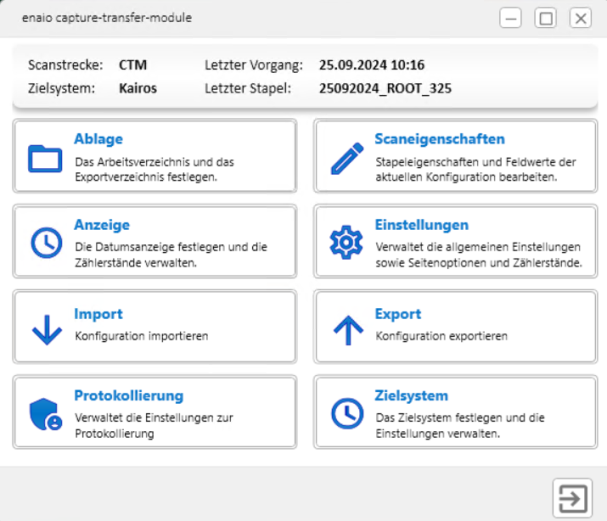
Konfiguration: Zielsystem
Im Bereich Zielsystem geben Sie das Zielsystem an: Classify oder Kairos.
Zielsystem Classify
Wenn Sie das Zielsystem Classify aktivieren, dann können Sie weiter zur Ablagekonfiguration navigieren.
Zielsystem Kairos
Für das Zielsystem Kairos muss der Service 'ai-connector' installiert sein. In der Konfigurationsdatei ai-connector-prod.yml des Services müssen die Kairos-Verbindungsdaten eingetragen sein.

-
Verifizierung
Eingebunden ist eine Verifizierungskomponente, die die Datei und die extrahierten Indexdaten anzeigt. Die Indexdaten können bearbeitet werden.
Die Verifizierungskomponente kann immer angezeigt werden oder nur, wenn die Erkennungsrate einen angegebenen Prozentsatz unterschreitet.
-
automatischer Import
enaio® capture-transfer-module kann verwendet werden, um PDF-Dateien aus einem Importverzeichnis automatisch zu indexieren und in enaio® zu importieren. Das Importverzeichnis wird über den Bereich Ablage angegeben.
Für den automatischen Import benötigen Sie eine Feldzuweisung.
-
Rechnungskonformitätsprüfung
Die Rechnungskonformitätsprüfung prüft, ob notwendige Daten extrahierten und zugeordnet werden können.
-
Server
Angeben werden die Verbindungsdaten zu enaio®. Die Verbindung kann getestet werden.
Für den automatischen Import wird eine Feldzuweisung zu den Feldern eines enaio®-Objekttyps benötigt.
Feldzuweisung
Für den automatischen Import von PDF-Dateien, deren automatischer Indexierung und dem Import in enaio® benötigen Sie eine Feldzuweisung.
Über die Feldzuweisung wählen Sie einen Dokumenttyp und als Standort ein Register aus.
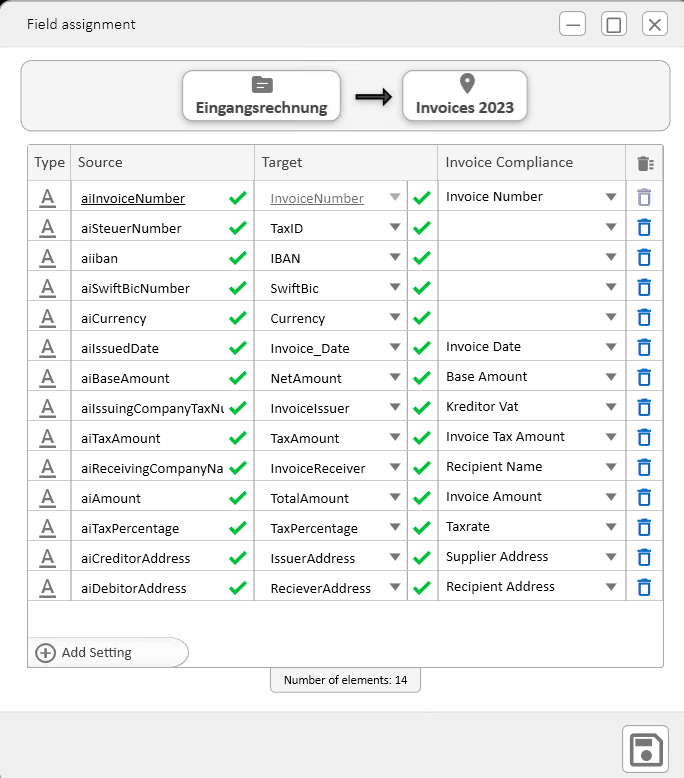
Angezeigt werden als Ziel die Felder des gewählten Dokumenttyps.
Notwendig ist die Zuordnung von benötigten Quell-Werten der kairos AI Cloud Services zu den Felder des Dokumenttyps.
| AI Quellen |
|---|
| aiReceivingCompanyName |
| aiIssuingCompanyName |
| aiAmount |
| aiInvoiceNumber |
| aiIssuedDate |
| aiBaseAmount |
| aiReceivingCompanyTaxNumber |
| aiIssuingCompanyTaxNumber |
| aiTaxAmount |
| aiTaxPercentage |
| aiIban |
| aiCurrency |
| aiReverseCharge |
| aiSupplyDate |
| aiTaxExempt |
| aiSteuerNumber |
| aiSwiftBicNumber |
Wenn die Rechnungskonformitätsprüfung aktiviert ist, dann ist ebenfalls eine Zuordnung von benötigten Rechnungskonformitätskriterien zu Feldern des Dokumenttyps notwendig.
| Rechnungskonformitätsfeld |
|---|
| Debitor Name |
| Debitor Adresse |
| Debitor MwSt |
|
Gesamtbetrag Der 'Gesamtbetrag' muss der Summe aus 'Rechnung Grundbetrag' und 'Rechnung Steuerbetrag' entsprechen. |
| Kreditor Name |
| Kreditor Adresse |
| Kreditor MwSt |
| Rechnung Grundbetrag |
|
Rechnung Steuerbetrag Der 'Rechnung Steuerbetrag' muss dem Produkt aus 'Rechnung Grundbetrag' und 'Steuersatz' dividiert durch 100 entsprechen. |
| Rechnungsdatum |
| Rechnungsnummer |
| Steuerbetrag |
| Steuersatz |
| Währung |
Konfiguration: Ablage
Im Bereich Ablage geben Sie Verzeichnisse an:
-
Exportverzeichnis
In diesem Verzeichnis werden die PDF-Dateien und die zugeordneten Daten in einer XML-Datei für den Import in enaio® classify gespeichert.
-
Arbeitsverzeichnis
In diesem Verzeichnis werden temporäre Daten gespeichert. Dieses Daten werden nach dem Beenden von enaio® capture-transfer-module wieder gelöscht.
-
Importverzeichnis
Aus diesem Verzeichnis können PDF-Dateien für den automatischen Import in enaio® über den Service 'ai-connector' übernommen werden.
Konfiguration: Protokollierung
Im Bereich Protokollierung geben Sie die Protokolldatei an und das Loglevel. Die aktuelle Protokolldatei kann geöffnet werden.

Konfiguration: Scaneigenschaften
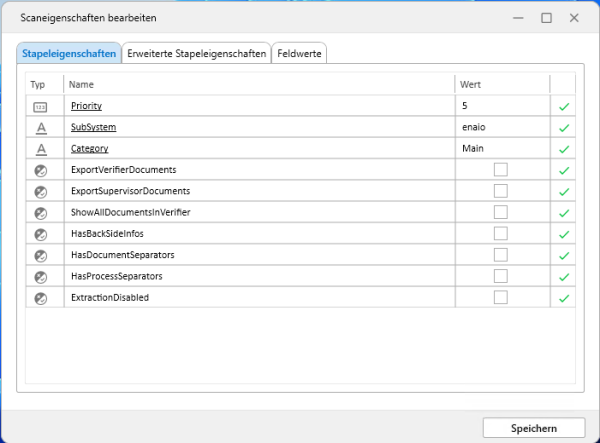
Der Bereich Scaneigenschaften ist unterteilt in drei Bereiche.
Bereich Stapeleigenschaften
enaio® classify benötigt Parameter, die in diesem Bereich unterstrichen als Pflichtfelder markiert sind und denen Werte zugeordnet werden müssen. Pflichtfelder sind Priority, Subsystem und Category.
Weitere Parameter in diesem Bereich sind optional und können, je nach Verarbeitung in enaio® classify, markiert werden.
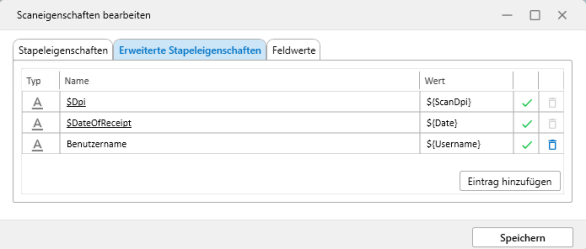
Bereich Erweiterte Stapeleigenschaften
Hier sind ebenfalls notwendige Parameter unterstrichen als Pflichtfelder markiert. Diese Parameter sind mit Standard-Werten vorbelegt. Über das Kontextmenü können Sie einen anderen Wert zuordnen.
Zusätzlich können hier weitere Einträge hinzugefügt und über das Kontextmenü Werte zugeordnet werden.
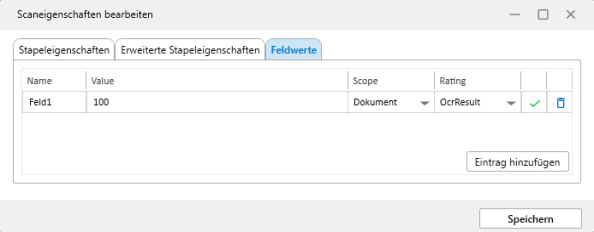
Bereich Feldwerte
enaio® classify benötigt gegebenenfalls Feldwerte, Kombinationen aus Name und Wert, die einem Scope zugeordnet werden.
Konfiguration: Anzeige
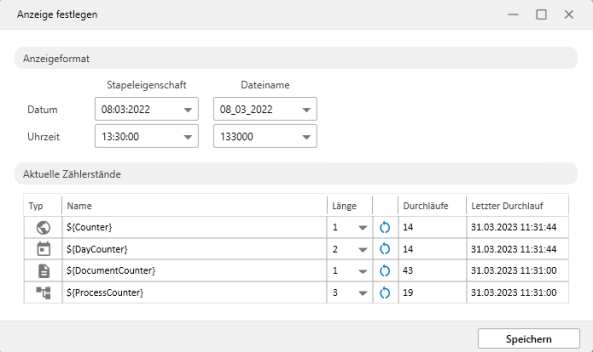
Hier legen Sie für Datum und Uhrzeit das Format fest für die entsprechenden Daten in der XML-Datei und in Dateinamen fest.
Das Format wählen Sie über die entsprechenden Listen.
Ebenfalls konfiguriert werden hier Zähler, die automatisch in den Durchläufen verwendet werden. Für jeden Zähler kann die Länge angegeben werden. Die aktuellen Zählerstände werden angezeigt und können zurück gesetzt werden. Das Datum des letzten Durchlaufs ist angezeigt.
-
Counter: Anzahl der Durchläufe
-
DayCounter: Anzahl der Durchläufe pro Tag
-
DocumentCounter: Anzahl der Dokumente
-
ProcessCounter: Anzahl der Vorgänge
Konfiguration: Einstellungen
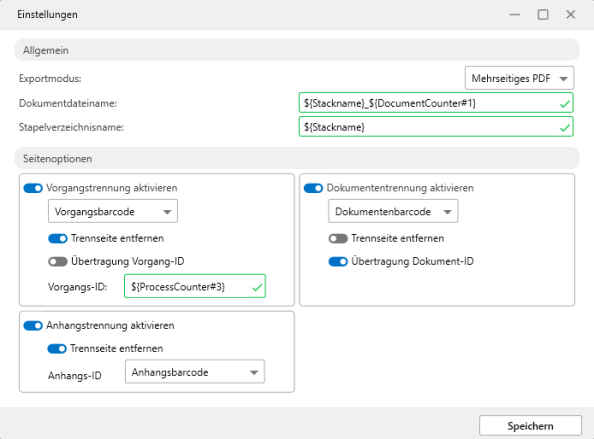
Einstellungen: Allgemein
Im Bereich Allgemein machen Sie folgende Angaben:
-
Exportmodus
Sie wählen, ob mehrseitige oder einseitige PDFs erzeugt werden.
-
Dokumentdateiname
Sie legen die Dokumentdateinamen fest. Über das Kontextmenü wählen Sie dazu Parameter aus.
-
Stapelverzeichnisname
Sie legen die Stapelverzeichnisnamen fest. Über das Kontextmenü wählen Sie dazu Parameter aus.
Einstellungen: Seitenoptionen
Im Bereich Seitenoptionen aktivieren Sie die Trennungen: Vorgangstrennung, Dokumententrennung und Anhangstrennung.
Zur aktivierten Trennung geben Sie an, wo sich die konfigurierten Barcodes als ID für die Trennung befinden. Sie können Trennseiten entfernen lassen.
Für die Vorgangstrennung legen Sie fest, ob die Vorgangs-ID übertragen werden soll oder ob stattdessen als Vorgangs-ID ein Wert verwendet werden soll. Der Wert wird über das Kontextmenü gewählt.
Für die Dokumententrennung legen Sie fest, ob die Dokumenten-ID übertragen werden soll.
Für die Anhangstrennung legen Sie fest, welcher Wert als Anhangs-ID verwendet wird.
Konfiguration: Export und Import
Konfigurationen können für den Austausch zwischen Entwicklungs-, Test- und Produktivsystemen exportiert und importiert werden.
 Bereiche können Sie einblenden. Alle ausgeblendeten Bereiche einer Seite blenden Sie über die Toolbar ein:
Bereiche können Sie einblenden. Alle ausgeblendeten Bereiche einer Seite blenden Sie über die Toolbar ein:
