Archiving Options
General archiving options related to the archiving enaio® server server are set in the Server > Settings > Server properties > Category: Data area of enaio® enterprise-manager.
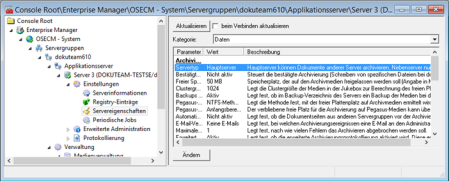
You can find the following parameters in the Archiving area:
- Server type
Main servers can archive documents of other servers; sub-servers can only archive their own documents. In case no media assignment has been set up for a given document type on the server that manages the corresponding documents, a main server will archive the documents of other main and sub-servers.
All servers of a server group must have the same server type.
- Confirmed archiving
In order to confirm that the documents were successfully archived, a file is created for every document type containing the data of the archived documents.
These files are saved in the \server\archive directory. They are named according to the following syntax: 'OSDDMMYY.'MainType''SubType''.
- Free storage space
You can define how much storage space (in MB) will remain free on the archiving medium in order to save the index data and data related to the object definition. This data will also be written to the media during archiving events.
The default value is 50 MB. Increase the value if you are using systems with more extensive object definitions and index data.
- Cluster size on the jukebox
The cluster size is used to determine the available space on media. The default value is '0' and the cluster size is automatically determined. The utilization of media capacity in jukeboxes, in particular in older jukebox models, can be improved by specifying the cluster size in MB. A size specified under media management takes precedence over the default value.
- Create backups
It is possible to create backup files of the archived documents and to save them to the \server\backup directory. The backup of a document is written to a subdirectory which is named after the medium on which the document has been archived.
- Pegasus method for calculating free media space
The default setting is 'NTFS method'; as a result, available space is determined using the WinApi32 function 'GetDiskFreeSpaceEx'.
When archiving to a Pegasus jukebox, the NTFS method used to determine free space on a medium may not always be reliable. As a result, a significant portion of the medium capacity may not be utilized.
The 'Pegasus method 1' is a method available from InveStore which determines free space by reading the '!FSFREE.###' file. This method is geared toward media larger than 4 GB.
The 'Pegasus method 2' is a method from InveStore which determines free space by reading the 'FSFREE__.###' file. This method is suitable for media smaller than 4 GB.
- Pegasus method for calculating the free space available for the next document to be archived.
The remaining free space for archiving on Pegasus media can be calculated based on the free space initially available or it can be re-calculated each time.
- Automatic prearchiving
When a main server archives documents of another server, all documents to be archived can be transferred before the archiving event to the main server for preparation. If a good network connection is available, this prearchiving step will not be unnecessary.
- Send e-mails when archiving
If an e-mail server is available, the administrator can be automatically notified about completed archiving processes by e-mail.
The following values are available:
'No e-mails'
'If no. of archiv. docs > 0 (w/o rep. file)'
'For each archiving process (w/o rep. file)'
'If no. of archiv. docs > 0 (with rep. file)'
'For each archiving process (with rep. file)'
'In case that errors occurred'
- Maximum number of archiving errors
You can specify after how many archiving errors the archiving process will stop. Enter '0' to not cancel the archiving process.
Note that updating the enaio® server will reset this value to '1'.
- Extended archive logging
You can establish whether extended archive logging remains activated. Thus, a detailed XML log file will be created. In addition to general data, the results of the hash and signature checks are listed in detail as well as the environment data concerning archiving.
- File name of the log file for extended archive logging
Specify the path and the name of the log file for extended archiving.
- Delete archived documents
You can specify whether or not to remove archived documents from the archiving medium. Depending on the medium used, this is not always possible, for example, by means of retention times.
If archived documents cannot be deleted, an error is logged with 'Delete archived document' and the file and index data are retained; the archived document can still be searched for. With 'Do not delete archived document', the file is always retained, the index data is deleted, and the archived document can no longer be searched for using the index data.
The user must have the appropriate system role in order to delete archived documents.
- Hash value check during archiving/dearchiving
Define whether or not to check the hash values during archiving or dearchiving processes. This ensures error-free transfer, though it will have an impact on performance.
This check is independent of the document integrity's validation.
- Archive object definition
Specifies whether to additionally archive the corresponding object definition during each archiving process.
If this option is disabled, you will need to ensure that the index data and the corresponding data model match the data in your process documentation.
- Retention times
Specifies the valid range for retention times.
32-bit systems may require you to limit the valid retention time. To do so, select the Unix time range. As a result it will not be possible to specify retention time beyond January 19, 2038.
If the file system in use allows retention times without any constraints, select the continuous time range.
When using NetApp archives, select the extended NetApp time range. As a result, the valid time range for retention times extends to January 19, 2071.
For GRAU DATA, select the continuous time range.
- Transfer retention times
For reference documents, the retention times are transferred from the original files.
Retention times of pre-archived documents are not transferred to new reference documents.
This option is highly resource intensive and may cause archiving runs to be significantly longer.
 areas. Use the toolbar to show all hidden areas at once:
areas. Use the toolbar to show all hidden areas at once:
