Technical Framework
This section is intended for expert-level users who want to learn more about the technical framework of enaio® data2ecm so that they can program new retrieval classes, for example.
Modules
The data export process was divided into several subtasks that are carried out in separate modules. The goal is to program the individual modules separately and combine them into projects during the configuration process to create an application.
Project-specific requirements can be fulfilled by programming separate modules.
It is possible to influence the behavior of the modules by adjusting the configuration settings.
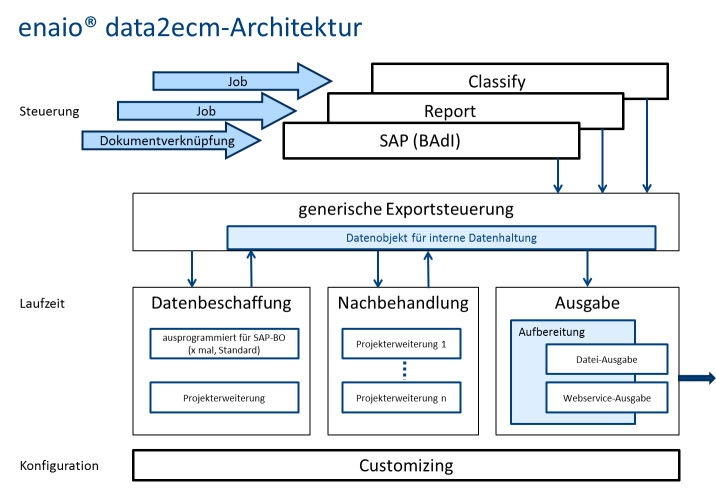
The sections below contain descriptions of the various module groups.
Data Retrieval
The data retrieval module obtains the data to be transferred to enaio®. It receives the search criteria as input data. The read data is written to a special object (see below: Data Object for Internal Data Storage).
The data retrieval object is based on the general concept of a business object. However, it does not necessarily only retrieve data related directly to the business object. It can also supply additional data. An example of this would be an invoice for which not only the actual invoice header and item data are searched, but also the data of the supplier (address, telephone number, etc.).
There are two options for entering the search criteria:
-
Directly in the search fields
-
Specifying a DocID.
The search fields are then defined according to the SAP object and the object key for the DocID.
Data retrieval modules are preconfigured for standard tasks, but they can also be rewritten as part of a project.
Data Object for Internal Data Storage
The data read by the data retrieval module must be passed on via several modules. A special display format is used that is implemented by the module for internal data storage. This is done in order to allow the task to be carried out generically and not tied to any specific project or data. This is an auxiliary module whose use is hard-wired into other modules. It can therefore not be replaced.
The data structure within the module is based on a table that may include one or more records.
Data is stored as name/value pairs in the records. Field values are therefore always passed on in the form of strings.
The individual records may contain embedded tables in addition to first-level values. These are stored in the data of a table control when they are exported to enaio®.
The object contains several auxiliary functions for adding and reading values.
Formatting
There may be differences between how data is displayed in SAP and the data format required by enaio®. In some cases, SAP field values will need to be converted for them to be evaluated correctly by the enaio®.
Examples of converted values include:
-
Adding or deleting of leading zeroes
-
Phone number normalization
-
Deleting of special characters
-
Number normalization
Formatting settings like this are provided via a method of a class. The formatting class for a field can optionally be specified in the configuration of the enaio® project.
A format method simply receives a field value as an input parameter and returns the formatted value as a string.
Data Preparation
In some projects it may be necessary to modify or supplement the data supplied by the data retrieval module. This can be done directly in the module. To avoid having to reprogram the entire data retrieval process, minor modifications and additions can be transferred to separate modules.
These modules only have the object for internal data storage as input and output parameters. They can read and modify the data contained in the object.
One example of data preparation would be adding the name of an enaio® cabinet based on field values, such as the company code.
Since data preparation is designed for use as a project-specific tool, there are no preconfigured modules available in the standard system.
Data Structure for Export Modules
The data that was read, formatted, and, if necessary, supplemented is transferred to the output controller. This transfers part or all of the data to the export data structure. In the process, the SAP-only data up to this point is supplemented with enaio®-specific information.
The export data structure is based on a class whose use is hard-coded in the various modules.
While the data is prepared in the output controller, the physical output takes place in a separate module.
Output Controller
In the output controller which is pre-programmed and cannot be replaced, the SAP data is evaluated by means of an enaio®-based configuration and transferred to the export data structure.
The enaio® system has its own data model which uses terms like cabinets, folders, registers, and documents. These components are structured hierarchically.
Conversely, the data acquired in SAP is available in a flat structure. You therefore have to define how the SAP data will be distributed to the enaio® components for each configuration. In addition, it is necessary to take action on the dataset already available in enaio®. Based on the relevant scenario, insertions or modifications depend on whether the target object already exists in enaio® or not. The dataset available in enaio® also determines whether reference documents or reference copies are created.
The output controller evaluates the configuration, retrieves enaio® data with the help of the specific output module, and decides on what actions to take based on the query results.
Since not all output modules allow online access to an enaio® system, the full range of functions of the application are not available when using these modules.
Physical Output
There are a number of mechanisms available for communication with the enaio® system and data output.
For each output operation there is a specific class which is addressed from the output controller. Allocation is defined via the configuration. This means it can be changed.
The following output options are currently supported:
-
Direct transfer to enaio® via web service
-
Output as a CSV file
-
Output as a CSV file with expanded header for enaio® classify
-
Output as an XML file
-
Screen output (for test purposes only).
If required, these output classes can be extended or fully reprogrammed.
Access to the enaio® Web Service
The web service supports the full functionality of the output interface. The web service allows you to create or modify enaio® objects online. To this end, a query to determine if the object exists is made before the write operation. The action taken in response to the search results is specified in the configuration.
In addition to transferring data, document links can also be created. This requires that SAP documents have been archived in a 'technical cabinet'.
If this is the case, a reference to a document in a technical cabinet can be created using the web service. The documents in the technical cabinet may consist of no more than one component to ensure they can be used as the target of a reference.
Several enaio® objects can be edited, but they must be in a hierarchical relationship to each other. One element of a hierarchy level can be created at a time during a call.
The web service can also transfer data for table controls.
Output to a CSV File
This output module is used to write a CSV file in which field contents are separated by a user-defined separator.
Direct communication with the enaio® server is not provided with this output variant. As such, all available data is output. The decision on whether to update or insert an enaio® object can then only be made during the actual import operation.
The CSV file has a header containing the names of the output fields.
As a matter of principle, no data can be output for table controls.
Even if there are several enaio® elements in the configuration, only one output line is created. This contains the data of all enaio® elements of an output operation.
Output as a Classify File
This variant is similar to output of data to a CSV file. The difference is that a more detailed header is generated.
Output to an XML File
The data to be output is prepared as an XML file. Here, too, the data of multiple enaio® objects is converted to create a flat structure.
Each record is enclosed in a <record> tag. There are tags inside this tag whose names correspond to the field name. For simple fields, the value to be output is added as text within the field name tags. Data for table controls (and field name tags, too) are enclosed line by line in <line> tags. These tags are inside the field name tag.
The entire content of the XML file is enclosed in a <record> tag.
Control Program
The basic purpose of the solution is to place recurring tasks in separate modules and combine them into an application based on the relevant project requirements.
The control program is used to combine the modules to create a functional application. This determines the total quantity (IDs) of business objects to be transferred and then calls the modules one by one to read and output all data.
It is possible for you to fully program this program by yourself. Because of this you can meet all the requirements of the relevant project.
Because the interfaces between the modules are modularized and standardized, however, it is possible to create output programs that work generically. For example, there is an implementation for a generic control program consisting of several classes and programs which, in addition to being generic, also offers the advantage of secure transmission via the queue concept.
Output with Queue
A queue is where the elements to be output are placed. Information for each element is stored that can be used to output elements at any time. Errors during the output operation are recorded in the queue in order that a new output attempt can be started later.
Errors during transfer are just one type of error. The retrieval classes can also trigger an error that disrupts the transfer of data. For example, certain retrieval classes, such as those for FI invoices, check whether the document to be output has already been fully posted. Transfer is blocked until all data is available.
If a new entry is added to the queue, the first export attempt is started immediately. If the export operation is successful, the element is deleted from the queue and added to a list of successfully exported elements.
A routinely scheduled job processes all elements in the queue.
The full queue output consists of the following elements:
-
Dictionary table for queue
-
Dictionary table for successfully exported elements
-
Class for queue entry handling
-
Class for generic export interface
-
Job to process elements in the queue
-
Application to analyze the queue (transaction /OSGMBH/DX_QADM).
The generic export interface currently offers two methods for creating a queue entry. They are each used to output ArchiveLink documents along with their metadata.
While the first method transfers an ArchiveLink DocID to identify a single document, the second one exports all documents of a given type that belong to a business object that must also be specified.
 areas. Use the toolbar to show all hidden areas at once:
areas. Use the toolbar to show all hidden areas at once:
